

SSML说明文档
SSML简介
语音合成标记语言(Speech Synthesis Markup Language, SSML)是一种基于XML的标记语言,用于提供语音合成的文本注释。用户通过给输入文本加上SSML中预先定义的标签,可以很好地指导合成器按照其需求进行操作。在接收到完整的SSML输入后,引擎对文本所有标签进行解析,再按长句(以句号、问好、感叹号结尾的句子称之为长句)输入后端合成声音。
在控制台使用SSML标签
在控制台上,可以为技能对话回复语设置SSML标签。
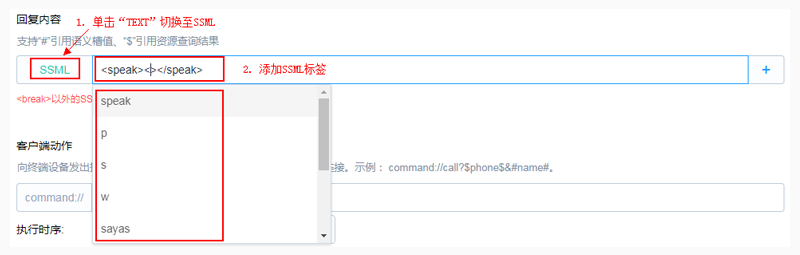
1. 进入意图编辑界面

2. 点击对话回复语输入框前的TEXT,即可切换成SSML标签格式。如果想切回TEXT,再次点击SSML即可。
Cloud-TTS SSML Tag支持列表
| 标签(Tag) | 是否支持 |
|---|---|
| speak | 支持 |
| paragraph/p | 支持 |
| sentence/s | 支持 |
| token/w | 支持 |
| sayas/say-as | 支持 |
| phoneme | 支持 |
| break | 支持 |
| prosody | 支持 |
| sub | 支持 |
SSML Tag 介绍
speak标签
所有SSML文档所必需的根标签,该标签有且仅能有一个,其他标签和文本都在该标签以内。< speak>可以包含< paragraph>/< p>,< sentence>/< s>,< token>/< w>,< sayas>/< sayas>,< phoneme>, < break>, < prosody>, < sub>标签。
示例:
<?xml version="1.0"?>
<speak version="1.1"
xmlns="https://www.w3.org/2001/10/synthesis"
xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://www.w3.org/2001/10/synthesis
http://www.w3.org/TR/speech-synthesis11/synthesis.xsd"
xml:lang="cn">
思必驰初创于2007年,由剑桥大学团队创立于英国剑桥高新区,2008年回国创业。是国内唯一拥有人机
对话技术,国际上极少数拥有自主产权、中英文综合语音技术(语音识别、语音合成、自然语言理解、声纹识
别、性别及年龄识别、情绪识别等)的公司之一,其语音技术曾经多次在美国国家标准局、美国国防部、国际
研究机构评测中夺得冠军,被中国和英国政府评为高新技术企业。思必驰团队使命:智能硬件和物联网时代,
让人机交互更有用、有趣。
语音合成和语音识别技术是实现人机语音通信,建立一个有听和讲能力的口语系统所必需的两项关键技术。
使电脑具有类似于人一样的说话能力,是当今时代信息产业的重要竞争市场。和语音识别相比,语音合成的技
术相对说来要成熟一些,并已开始向产业化方向成功迈进,大规模应用指日可待。
</speak>
paragraph/p标签
一对< p>< /p>标签或者< paragraph>< /paragraph>标签中的内容为一段文本。对于未加该标签的文本,引擎会自动将其合并为一个paragraph。< paragraph>/< p>可以包含< sentence>/< s>,< token>/< w>,< sayas>/< say-as>,< phoneme>,< break>, < prosody>, < sub>标签。可以包含于```标签。
示例:
<?xml version="1.0"?>
<speak version="1.1"
xmlns="https://www.w3.org/2001/10/synthesis"
xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://www.w3.org/2001/10/synthesis
http://www.w3.org/TR/speech-synthesis11/synthesis.xsd"
xml:lang="cn">
<paragraph>思必驰初创于2007年,由剑桥大学团队创立于英国剑桥高新区,2008年回国创业。是国内唯一拥有人机对话技术,国际上极少数拥有自主产权、中英文综合语音技术(语音识别、语音合成、自然语言理解、声纹识别、性别及年龄识别、情绪识别等)的公司之一,其语音技术曾经多次在美国国家标准局、美国国防部、国际研究机构评测中夺得冠军,被中国和英国政府评为高新技术企业。思必驰团队使命:智能硬件和物联网时代,让人机交互更有用、有趣。</paragraph>
<p>语音合成和语音识别技术是实现人机语音通信,建立一个有听和讲能力的口语系统所必需的两项关键技术。使电脑具有类似于人一样的说话能力,是当今时代信息产业的重要竞争市场。和语音识别相比,语音合成的技术相对说来要成熟一些,并已开始向产业化方向成功迈进,大规模应用指日可待。</p>
</speak>
sentence/s标签
一对< s>< /s>标签或者< sentence>< /sentence>标签中的内容为一个长句子(以句号、问号、感叹号结尾的句子称之为长句子)。对于sentence标签之外的文本,引擎会按照标点符号进行切分,并自动将内容添加到一个新的sentence节点下面。 < sentence>/< s>可以包含< token>/,< sayas>/< say-as>,< phoneme>,< break>, < prosody>, < sub>标签。可以包含于< speak>、< prosody>、< paragraph>/< p>标签。
示例:
<?xml version="1.0"?>
<speak version="1.1"
xmlns="https://www.w3.org/2001/10/synthesis"
xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://www.w3.org/2001/10/synthesis
http://www.w3.org/TR/speech-synthesis11/synthesis.xsd"
xml:lang="cn">
<paragraph>思必驰初创于2007年,由剑桥大学团队创立于英国剑桥高新区,2008年回国创业。是国内唯一拥有人机对话技术,国际上极少数拥有自主产权、中英文综合语音技术(语音识别、语音合成、自然语言理解、声纹识别、性别及年龄识别、情绪识别等)的公司之一,其语音技术曾经多次在美国国家标准局、美国国防部、国际研究机构评测中夺得冠军,被中国和英国政府评为高新技术企业。思必驰团队使命:智能硬件和物联网时代,让人机交互更有用、有趣。</paragraph>
<p>语音合成和语音识别技术是实现人机语音通信,建立一个有听和讲能力的口语系统所必需的两项关键技术。
<s>使电脑具有类似于人一样的说话能力,是当今时代信息产业的重要竞争市场。</s><sentence>和语音识别相比,语音合成的技术相对说来要成熟一些,并已开始向产业化方向成功迈进,大规模应用指日可待。</sentence></p>
</speak>
token/w标签
一对< w>< /w>标签或者< token>< /token>标签中的内容为一个语法词。对于token标签之外的文本,引擎会进行分词,并自动将词面文本添加到一个新的w节点下面。token/w 可以包含< phoneme>、< sub>, 可以包含于< speak>,< prosody>,< paragraph>/< p>,< sentence>/< s>标签。
<?xml version="1.0"?>
<speak version="1.1"
xmlns="https://www.w3.org/2001/10/synthesis"
xmlns:xsi="https://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://www.w3.org/2001/10/synthesis
http://www.w3.org/TR/speech-synthesis11/synthesis.xsd"
xml:lang="cn">
<paragraph>思必驰初创于2007年,由剑桥大学团队创立于英国剑桥高新区,2008年回国创业。是国内唯一拥有人机对话技术,国际上极少数拥有自主产权、中英文综合语音技术(语音识别、语音合成、自然语言理解、声纹识别、<w>性别</w>及年龄识别、情绪识别等)的公司之一,其语音技术曾经多次在美国国家标准局、美国国防部、国际研究机构评测中夺得<token>冠军</token>,被中国和英国政府评为高新技术企业。思必驰团队使命:智能硬件和物联网时代,让人机交互更有用、有趣。</paragraph>
<p>语音合成和语音识别技术是实现人机语音通信,建立一个有听和讲能力的口语系统所必需的两项关键技术。
<s>使电脑具有<token>类似</token>于人一样的说话能力,是当今时代信息产业的重要竞争市场。</s>
<sentence>和语音识别相比,<w>语音合成</w>的技术相对说来要成熟一些,并已开始向产业化方向成功迈进,大规模应用指日可待。</sentence></p>
</speak>
sayas/say-as标签
指明元素中包含的文本性质,即文本的发音方式。say-as/sayas不可以包含任何标签,只能包含文本;可以包含于< speak>、< paragraph>/< p>、< sentence>/< s>、< prosody>标签。
| 属性 | 说明 | 是否支持 |
|---|---|---|
| interpret-as | 必需,指明文本的发音方式。可用值是包含类型名称的串。 | 是 |
| format | 可选,指明文本格式。可用值是包含类型名称的串。值依赖interpret-as。 | 是 |
| detail | 可选,指明元素中包含的文本类型。可用值是包含类型名称的串。"string":extension是使用类型的扩展格式说明detail属性的取值,例如,detail="date:dmy"。 | 是 |
| type | 可选,CSSML1.0中定义,和detail等效。 | 是 |
属性interpret-as的可选值
| 发音方式 | 说明 |
|---|---|
| number | 指明是数字 |
| telephone | 按电话号码读法发音 |
| date | 指明日期 |
| time | 指明时刻 |
| duration | 指明时间段 |
| currency | 指明货币金额 |
| measure | 指明度量值 |
| name | 指明是人的姓名、公司名称或是地名 |
| net | 指明是网络(internet)上应用的地址 |
| address | 指明是表述邮政地址 |
属性format的可选值
| interpret-as的属性值 | format取值 | 说明 |
|---|---|---|
| number | 具体见下表 | |
| date | dmy, mdy, ymd,ym, my, md, y | 指明年月日的顺序,d=day, m=month,y=year |
| time | hm, hms | 指明是否时间(小时/分钟/秒)的格式和顺序,h=hour, m=minute, s=second |
| duration | hm, hms, ms | 指明是否时间间隔(小时/分钟/秒)的格式和顺序 |
| net | email, url | 分别表示网络电子邮件地址和网络URL地址 |
number 的format取值和说明
| format取值 | 说明 |
|---|---|
| ordinal | 按数值发音 |
| digits | 按数字串发音 |
| score | 按比分读法发音 |
| fraction | 按分数读法发音 |
属性detail的可选值
| 类型 | 扩展格式 | 说明 |
|---|---|---|
| number | 包含的文本应该按数字发音。 | |
| number | ordinal | 包含的文本应该按数值发音。 |
| number | digits | 包含的文本应该按数字串发音。 |
| number | score | 包含的文本应该按比分读法发音。 |
| number | fraction | 包含的文本应该按分数读法发音。 |
| date | dmy, mdy, ymd,ym, my, md, y | 包含的文本在指定格式中是日期。在格式扩展中,d=day, m=month,y=year。如果不包括扩展格式,合成系统默认日期格式为月日。 |
| time | hm, hms | 包含的文本为时间。用数字描绘时、分和秒,中间要用冒号分开。下面的时间串是正确的例子:12:35; 1:14:32;08:15; 02:50:45。在格式扩展中,h=hour, m=minute,s=second。 |
| duration | hm, hms, ms | 包含的文本是时间段。 |
| currency | 包含的文本是货币金额。 | |
| measure | 包含的文本是度量值。 | |
| telephone | 包含的文本是电话号码。 | |
| net | 包含的文本是电子邮件地址。 | |
| net | url | 包含的文本是URL。 |
| address | 包含的文本是邮政地址。 | |
| name | 包含的文本是名称。 |
< say-as>相当于< sayas>。
开始和结束的元素必须相同。规范禁止这样的序列:< sayas> text < /say-as> 。
对于规范的文本,语音合成系统通常能够自动处理类似以上所指的这些情况。在自动处理出错时,推荐使用say-as元素,这样可以提示合成系统正确识别文本的朗读方式,改善合成效果。
对于文本中包含的多个文本域的文本格式,应使用单一的、非字母的字符将其分隔。例如,say-as元素中包含的日期值可以通过连字号或斜线分离成日、月、年,如10-19-02或10/19/02。
示例:
<?xml version="1.0" encoding="utf8"?>
<speak xml:lang="cn">
<p>
上海交通大学的英文缩写是<sayas type="acronym">SJTU</sayas>
网址是<sayas interpret-as="net" format="url">http://www.sjtu.edu.cn</sayas>
技术支持信箱是<sayas interpret-as="net" format="email">
devsupport@aispeech.com </sayas>
<sayas type="spell-out">SDK</sayas>
现在时钟已指向<sayas type="number">8</sayas>
我们一共有<sayas type="number:ordinal">13</sayas>个人
我住在<sayas type="number:digits">412</sayas>房间
双方比分是<sayas type="number:score">3:1</sayas>
取其中的<sayas type="number:fraction">1/3</sayas>
今天是<sayas type="date:ymd">2000/12/13</sayas>
会议<sayas type="time:hm">14:30</sayas>开始
笔试时间<sayas type="duration">8:00-10:00</sayas>
这本书的价格是<sayas type="currency">¥12.33</sayas>
身高是<sayas type="measure">1.5米</sayas>
商务合作的电话是<sayas type="telephone">18015588312</sayas>
我的邮箱是<sayas type="net:email">aicloud@aispeech.com</sayas>
本公司的网址是<sayas type="net:url">www.aispeech.com</sayas>
你可以写信至<sayas type="address">苏州市工业园区创意产业园</sayas>
他是<sayas type="name">吴小珍</sayas>
</p>
</speak>
phoneme标签
指明标签内文本的读音。读音长度需和文本长度一致。目前仅支持带调汉语拼音,读音通过py属性给出。拼音之间用单个空格隔开。 phoneme标签不可以包含任何标签,只能包含文本;可以包含于< speak>,< paragraph>/< p>, < sentence>/< s>, < w>/< token>, < prosody>标签。
<?xml version="1.0" encoding="utf8"?>
<speak xml:lang="cn">
<sentence>
他姓<phoneme py="zeng1 hang2">曾行</phoneme>
</sentence>
</speak>
break标签
在音频中加入指定时长的停顿。如果break元素的属性指明strength和time,则以time的值为准;如果两则都没有指明,则停顿时间为自然韵律词边界的停顿长度。break标签不可以包含任何标签,可以包含于< speak>,< paragraph>/< p>,< sentence>/< s>,< prosody>。
| 属性 | 说明 |
|---|---|
| strength | 可选,指明停顿长短。可取值: "x-weak", "weak", "medium"(default value), "strong", or "x-strong" |
| time | 可选,指明具体停顿时长。以秒或毫秒为单位,例如3s或250ms。 |
prosody标签
指明合成文本时的音高、速率和音量等韵律参数。prosody可以包含< sentence>/< s>、< w>/< token>, < phoneme>,< break>,< sub>标签。prosody可以包含于< speak>、< paragraph>/< p>、< sentence>/< s>。
属性
| 属性 | 说明 | 是否支持 |
|---|---|---|
| pitch | 可选,指明基频的高低。可取值绝对频率数值、相对值。绝对频率数值可以取60~480Hz,或下列值:"xlow","low", "medium", "high", "x-high", or "default"。相对值可以取浮点值、浮点百分率。 | 是 |
| rate | 可选,指明速率。rate的取值可以是绝对值,或相对值。绝对值可以取0.5~1.5中的小数表明语速的比例,或下列值:"x-slow", "slow", "medium", "fast", "x-fast",or "default"。相对值可以取浮点值或浮点百分率。 | 是 |
| volume | 可选,指明合成语音的音量。可取值绝对值,或相对值。绝对值可以取0~100中的正整数或小数,或下列值:"silent", "x-soft", "soft", "medium", "loud", "xloud",or "default"。相对值可以取浮点值,或浮点百分率。默认volume的值是100。 | 是 |
示例:
<?xml version="1.0" encoding="utf8"?>
<speak xml:lang="cn">
<s>
<prosody pitch="high" rate="slow" volume="loud">让世界倾听我们的声音,</prosody>
<prosody pitch="-10%" rate="+0.5" volume="0">你能听见吗?</prosody>
</s>
</speak>
Prosody默认值列表
音量
| 名称 | 默认值 |
|---|---|
| default | 100 |
| silent | 1 |
| x-soft | 30 |
| soft | 65 |
| medium | 100 |
| loud | 150 |
| x-loud | 230 |
音速
| 名称 | 默认值 |
|---|---|
| default | 100% |
| x-slow | 60% |
| slow | 80% |
| medium | 100% |
| fast | 125% |
| x-fast | 150% |
基频
| 名称 | 默认值 |
|---|---|
| default | 100% |
| x-low | 70% |
| low | 85% |
| medium | 100% |
| high | 110% |
| x-high | 120% |
sub 标签
使用指定的文本替换原有文本的发音,如果指定的文本为空,则不发音。使用sub元素
替换原来文本中的内容,或者是让一段文本不发音。sub不可以包含任何标签,只能包含文本;可以包含于< speak>、< paragraph>/< p>、< sentence>/< s>、< prosody>。
| 属性 | 说明是否支持 |
|---|---|
| alias | 必需,指定替换后的文本。 |
<?xml version="1.0" encoding="GB2312"?>
<speak xml:lang="cn">
<sentence>
中国是<sub alias="世界贸易组织">WTO</sub>的成员
</sentence>
</speak>
emphasis 标签
将包含的文本进行强调。
<?xml version="1.0"?>
<speak version="1.1" xml:lang="en-US">
That is a <emphasis> big </emphasis> car!
</speak>
附录
用户组合使用prosody里的各种属性,可以调节出不同的语音效果,甚至情感变化。